Using R to Datamine Twitter - Intro
First - set-up a developer account with Twitter
In order to submit data requests to Twitter, you need a developer account. Go to Twitter Developers https://dev.twitter.com/, aka. Fabric.
- Click “More”” and “Get Started with Fabric”
- Fill out your name and email to request an account
- Mine took a week to get an approval email
- Once you get the email invitation, follow the instructions to activate your account.
- Go to the Twitter Applications manager at https://apps.twitter.com/
- Create a new app - fill out the required fields
- Generate a consumer key - save the consumer key and consumer secret
- Generate the access token and secret
Learn more at the Credera Blog
- go to at http://blog.credera.com/business-intelligence/twitter-analytics-using-r-part-1-extract-tweets/
- see more posts at http://blog.credera.com/?s=twitter
Getting started in R
You will need to install the following packages in R: twitteR and ROAuth for “talking: to Twitter. You also need the tm and wordcloud packages to create the wordlcoud figure.
install.packages("twitteR")
install.packages("ROAuth")
library("twitteR")
library("ROAuth")
install.packages("tm")
library("tm")
install.packages("wordcloud")
library("wordcloud")Get your authenticated credentials (CAcert and cURL)
For Windows’ users you need to get the cacert.pem file. This gets stored in your local directory so be sure that your working directory is set how you want it. Run getwd() to check what R thinks is your current working directory. Use setwd(c:/xxxx/xxxx) to set the path to what you want.
Some Important Notes
IMPORTANT NOTE - at my twitter developer site I had to update the permissions for the app to be read, write and direct messages see https://apps.twitter.com/app/7358826 then the steps below worked - with just read permissions I kept getting “Authorization Required” error…
[1] "Authorization Required"
Error in twInterfaceObj$doAPICall(cmd, params, "GET", ...) :
Error: Authorization RequiredNow that you have your Twitter application configured for read, write and direct messages permissions, download the CAcert.
download.file(url="http://curl.haxx.se/ca/cacert.pem",destfile="cacert.pem")Next create an object with the authentication details for later sessions. You will need your consumer Key and Secret from your Twitter app to input here.
# create an object "cred" that will save the authenticated object that we can use for later sessions
# input your own consumerKey and Secret below
cred <- OAuthFactory$new(consumerKey='xxxxxxxxxxxxxxxxxxxxxxxxx',
consumerSecret='xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx',
requestURL='https://api.twitter.com/oauth/request_token',
accessURL='https://api.twitter.com/oauth/access_token',
authURL='https://api.twitter.com/oauth/authorize')
# Executing the next step generates an output --> To enable the connection, please direct your web browser to: <hyperlink> . Note: You only need to do this part once
cred$handshake(cainfo="cacert.pem")
#save for later use for Windows
save(cred, file="twitter_authentication.Rdata")
# Load "twitter authentication.Rdata" file in your session and then run registerTwitterOAuth.
# This should return "TRUE" indicating that all is good and we can proceed.
load("twitter_authentication.Rdata")
registerTwitterOAuth(cred)Next do a search on twitter and parse through the tweets and create a wordcloud
search.string <- "#nursing"
no.of.tweets <- 1499
tweets <- searchTwitter(search.string, n=no.of.tweets, cainfo="cacert.pem", lang="en")This may take a few minutes to run depending on the amount of tweets being extracted.
Here are some of the tweets extracted using head(tweets) to pull the first few tweets extracted.
[[1]]
[1] "stjoehealthjobs: #Nursing #Job in #FULLERTON, CA: Patient Care Tech, Oncology, FT, Nights, 12hr at St. Joseph's Health http://t.co/gL1puLnlxS"
[[2]]
[1] "ILnursejobs: #nursing #jobs Nurse Practitioner at Healthstat (IL): Nurse Practitioner (5 hrs/wk) Needed at On-Site Employer... http://t.co/ngP4ykfbFZ"
[[3]]
[1] "ILnursejobs: #nursing #jobs PRN Endoscopy Nurse at Advocate Health Care Network (Barrington): For more than 35 years, Good ... http://t.co/ngP4ykfbFZ"
[[4]]
[1] "ILnursejobs: #nursing #jobs On the search for another quality NP for Psych just NW of Chicago at http://t.co/KXqT9XjNNF (IL)... http://t.co/ngP4ykfbFZ"
[[5]]
[1] "ILnursejobs: #nursing #jobs STAFF NURSE I at Provena Saint Joseph Medical Center (Evanston, IL): STAFF NURSE I Facility Pre... http://t.co/ngP4ykfbFZ"
[[6]]
[1] "dreytoledo: God is so GOOD! í ½í¸,í ½í²Tí ½í²sí ½í²< #life #financial #problems #nursing http://t.co/1OS0EV2MeA"The next set of commands will parse through these tweets and extract the key words we will use in the final wordcloud.
# create a function to extract text
tweets.text <- sapply(tweets, function(x) x$getText())
#convert all text to lower case
tweets.text <- tolower(tweets.text)
# Replace blank space ("rt")
tweets.text <- gsub("rt", "", tweets.text)
# Replace @UserName
tweets.text <- gsub("@\\w+", "", tweets.text)
# Remove punctuation
tweets.text <- gsub("[[:punct:]]", "", tweets.text)
# Remove links
tweets.text <- gsub("http\\w+", "", tweets.text)
# Remove tabs
tweets.text <- gsub("[ |\t]{2,}", "", tweets.text)
# Remove blank spaces at the beginning
tweets.text <- gsub("^ ", "", tweets.text)
# Remove blank spaces at the end
tweets.text <- gsub(" $", "", tweets.text)
#create corpus
tweets.text.corpus <- Corpus(VectorSource(tweets.text))
#clean up by removing stop words
tweets.text.corpus <- tm_map(tweets.text.corpus, function(x)removeWords(x,stopwords()))Here is what the cleaned up text now looks like for the 1st tweet extracted above.
tweets.text.corpus[1]$content
[[1]]
<<PlainTextDocument (metadata: 7)>>
nursing job fulleon ca patient care tech oncology ft nights 12hr st josephs healthFinally, generate the wordcloud for all of the extracted content from these 1499 tweets.
#generate wordcloud
wordcloud(tweets.text.corpus,min.freq = 2, scale=c(7,0.5),colors=brewer.pal(8, "Dark2"), random.color= TRUE, random.order = FALSE, max.words = 150)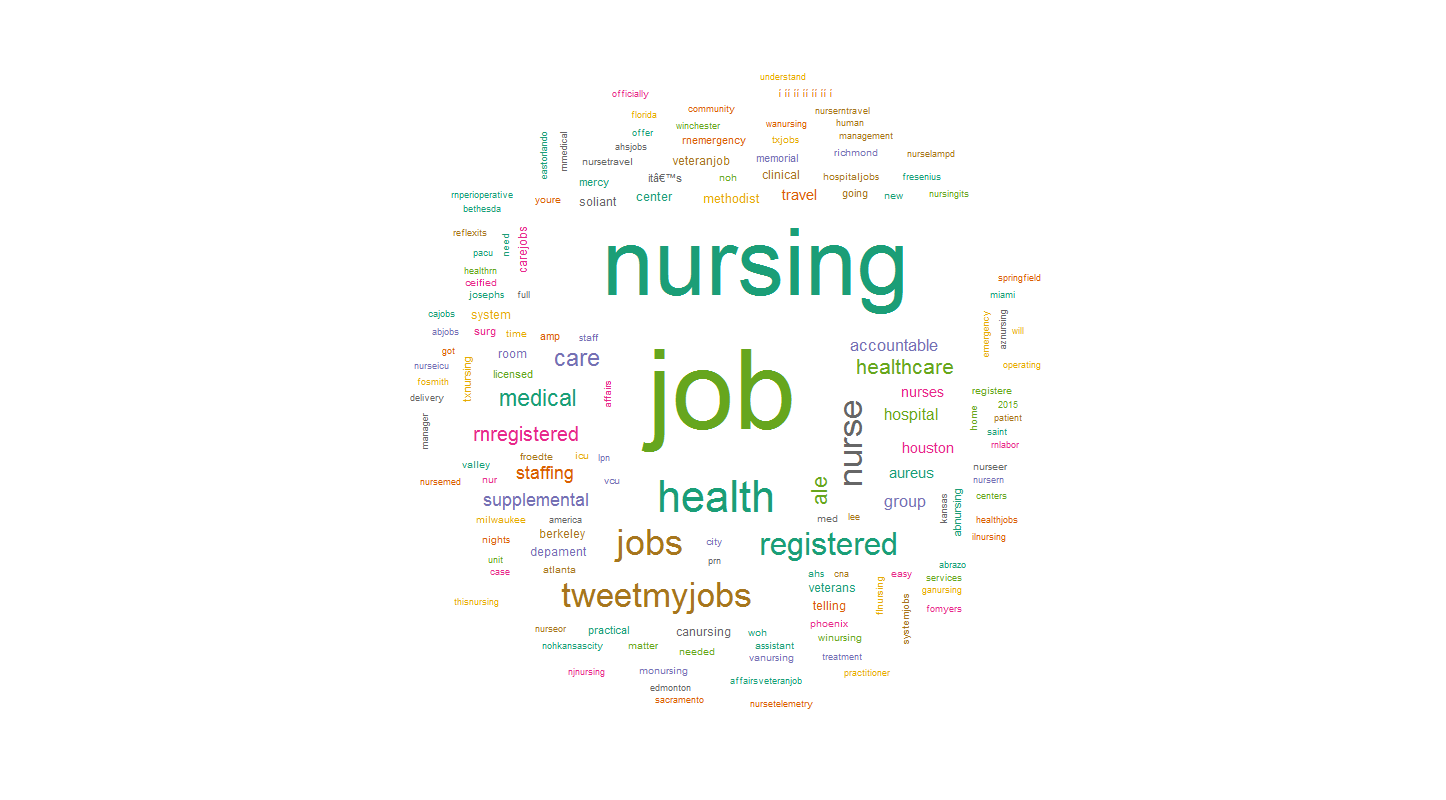
comments powered by Disqus
MELINDA HIGGINS, Ph.D.
Biostatistician and Chemometrician
FOLLOW MELINDA HIGGINS
FORK MY GUTHUB BLOG